本記事は、ローカル LLM を使ってテスト駆動開発のように記事執筆を進められるのでは...?という妄想のもと、実際に試してみた実験の記録です。もしよろしければお付き合いください。
はじめに
テスト駆動開発 (TDD) というプラクティスがあります。 「レッド・グリーン・リファクタリング」という3つのステップを繰り返し、プログラムの機能を追加する前に、その機能が満たすべき仕様を定義するテストコードを先に書く開発手法です [1] 。
このプラクティスを実践することで得られる恩恵の1つが、先んじて要求をテストコードとして定義しておくことでゴールを明確化できることです。 つまり、具体的な実装を始める前に俯瞰的な視点に立ち、目的を考えることが強制されるとも言えます。
この利点を記事の執筆にも適用できないものかと妄想しました。言うなれば「テスト駆動ライティング」です [4] 。ブログ執筆において具体的な内容を書き始める前に、伝えたいこと (=仕様) を先に考え、テストコードとして記述しておくことで、執筆のリズムを作ろうというものです。
従来、定量的な関数の評価とは異なり、「文章を評価する」というタスクは定性的なものであり、簡単に実現できるものではありませんでした。 しかし LLM が普及し、API を使えば誰でも簡単に推論を行えるようになった [2] ことで、文章の質の評価も簡単に行えるようになりました。 さらに昨今ではローカルで動作する LLM がたくさん公開されており、低コストに実行する手段も増えました。
そこでテストフレームワークを用いて、ローカル LLM で実際に記事を"テスト"しながら、執筆を進める試みをやっていきます。
なお、近年では高性能なモデルを使って「自分の文体で文章の叩きを作らせ、手直しして記事とする」という潮流もありますが、ここではあくまで自分の手で文章を書くことを中心にしつつ、LLM の力を借りて文章をブラッシュアップしていく使い方を想定しています。
先にまとめ
- Ollama と Vitest を使って、記事の品質を繰り返し評価できる TDD ライクな仕組みを作ってみた
- 良かった点
- テーマ (=仕様) を先に考えるという強制力が働く
- ペアライティングの感覚で執筆を進められる
- API コストを気にしなくて良い
- 改善できそうな点
- テスト実行に時間がかかる
- 評価がブレたり、甘くなったりすることがある
- テストケースの書き方の自由度が高く、改善の余地がある
テスト実行の仕組み
今回、Ollama と Vitest を使ってテスト実行を行う仕組みを作成しました。 Ollama は手元の PC 環境で LLM を実行・管理できるオープンソースのツール、そして Vitest は JavaScript/TypeScript 向けのテストフレームワークです。
テストファイル内でテストケースを作成し、各ケースにおいて Ollama 経由でローカル LLM を呼び出して記事を評価させ、結果を取得します。 Ollama は Structured outputs に対応しているため、JSON schema を渡すことで構造化されたデータを取り出すことが可能です。
今回はローカルのモデルとして Google が提供している Gemma 3 12B を利用します。
実行環境は以下の通りです:
- MacbookPro M2 Pro 32 GB
- 言語: TypeScript
- 主なライブラリ:
- Vitest
- Ollama (Gemma 3 12B)
- Zod v4
「テスト駆動ライティング」の流れ
テスト駆動ライティングは以下のような流れで進めます。
- テスト用のプロジェクトをセットアップ
- 記事のマークダウンファイルを用意する
- テストを書く
- テストを失敗する
- 内容を書いていく
- テストによるフィードバックを受けながら修正する
実際に各ステップを簡単に説明していきます。 サンプルコードはこちらに載せています。
1. セットアップ
まずは、テストを回すためのプロジェクトを用意します。 必要なライブラリをインストールします。
mkdir test-driven-writing
cd test-driven-writing
pnpm add zod ollama gray-matter
pnpm add -D vitest typescript @types/node
Vitest の config を下記のように定義しておきます。
import { defineConfig } from "vitest/config";
export default defineConfig({
test: {
testTimeout: 0,
},
});
testTimeout を 0 に設定しているのは、デフォルトのタイムアウトを無効化するためです。 LLM の呼び出し→結果の取得には時間がかかるので、タイムアウトしてしまうことを防ぎます。
2. マークダウンファイルを用意する
続いて好きな場所にマークダウンファイルを作成します。 上で作成したプロジェクト内でも良いですし、もしすでにブログの環境が存在する場合はその中に作るのが良さそうです。 自分はブログ記事を Obsidian 上で markdown で書いている [3] ので、そちらのプロジェクト上に作成します。
また、今回の実験では frontmatter を用いて、記事固有のコンテキスト (タイトルやテーマなど) をメタデータとして管理します。 具体的には以下のような情報を frontmatter に追加しました:
title: 記事のタイトルthemes: 記事のテーマ・伝えたいことtarget_readers: 記事の対象読者
---
title: "テスト駆動ライティング"
themes:
- テスト駆動開発に着想を得た「テスト駆動ライティング」は成り立つのかを実験する
- ローカル LLM 活用の1つのアイデアを提供する
- テスト駆動ライティングの実用性、およびメリット・デメリットを考える
target_readers:
- ブログをやっている、記事執筆に興味がある
- ローカル LLM の活用方法を検討している
---
<!-- ここに本文を書く -->
これらは、最初にバチッと決めるのは難しいです。 しかし導入でも書いた通り、先にこの抽象的な、俯瞰的な部分を考える時間を少しでも取ることで、何について書きたいのか、記事の輪郭 (=目的) をよりハッキリさせることに繋がります。
完璧である必要は無いし、書きながら加筆修正を加えてもよい、というモチベーションで進めます。
3. テストを書く
それでは早速テストを check.test.ts として書いてみます。
まず、記事を評価するポイントを以下のように置いてみました。
- テーマ: 記事の内容がテーマに合致するものになっているか
- 対象読者: 記事の内容が対象読者にふさわしいものになっているか
- 文章の流れ: 文章の流れが自然で読みやすいものになっているか
- タイトル: タイトルが記事の内容にふさわしいものになっているか
コード (抜粋) は以下のようになります。
// ...
describe("テスト駆動ライティング", () => {
it("テーマ", async () => {
// role にテストケース固有の指示を入力し、createPrompt で prompt を生成する
// そして ollama を用いてローカル LLM 経由でレスポンスを生成する
const role = `
- 記事がテーマに合致したものになっているかを評価してください
`;
const response = await ollama.generate({
model,
format,
prompt: createPrompt(role),
});
// 生成結果を parse し、ログ出力する
const evaluation = parseContent(response.response);
printResult(evaluation);
// 評価結果を検証し、期待される条件を満たしているか確認する
expect(evaluation.is_passed, `テスト不合格: ${evaluation.feedback}`).toBe(
true
);
// ここではスコアが70点以上であることを確認する
expect(
evaluation.score,
`スコアが基準値未満です: ${evaluation.score}点\nフィードバック: ${evaluation.feedback}`
).toBeGreaterThanOrEqual(70);
});
it("対象読者", async () => { /* 省略 */ });
it("文章の流れ", async () => { /* 省略 */ });
it("タイトル", async () => { /* 省略 */ });
});
プロンプトは、ベースとなるプロンプトを用意したうえで、テストケースに応じてその内容を変えます。 具体的には createPrompt という関数を用意して、共通なプロンプトはフォーマット化しつつ、評価したい観点を差し込めるようにしています。実装例は以下のとおりです。
const createPrompt = (role: string) => {
return `あなたはブログ記事を評価する文章作成の専門家です。
指定された条件を満たしているかどうかを評価し、フィードバックを提供することが目標です。
まず、ブログ記事のテーマとターゲットオーディエンスを確認してください:
<theme_and_target>
- ブログのテーマ: ${
frontmatter.themes ? frontmatter.themes.join(", ") : "未設定"
}
- ターゲット読者: ${
frontmatter.target_readers
? frontmatter.target_readers.join(", ")
: "未設定"
}
</theme_and_target>
次に、評価にあたって注意するべきルールを確認してください:
<rules>
- \{\% linkcard /\%\} のような記法は、独自に設定しているものなので、使用して問題ありません
</rules>
続いて、あなたが評価するべき観点を確認してください:
<role>${role}</role>
以下の記事を注意深く読み、分析してください:
<title>${frontmatter.title || "未設定"}</title>
<article>${articleText}</article>
分析後、記事を1から100のスケールで採点してください。1は完全にトピックから外れている、100はテーマとターゲットオーディエンスと完璧に合致している、とします。
評価に基づいて、記事が基準を満たしているかどうかを判断してください。記事は70点以上を獲得し、テーマの主要ポイントを十分に扱っている場合に合格と見なされます。
評価を以下のJSON形式にまとめてください:
{
"is_passed": boolean,
"score": integer,
"feedback": "評価の簡潔な要約を提供し、主な長所と改善点を含めてください。なぜその点数を付けたのか、そして記事が基準を満たした、または満たさなかった理由を説明してください。"
}
フィードバックは建設的で具体的なものにし、必要に応じて改善のための実行可能な提案を提供してください。
`;
};
ポイントとしては下記の点があります:
roleを引数で渡せるようにし、テストケース毎に指示文を変えてプロンプトを作成できるようにするfrontmatterから記事の内容に関するメタデータを抽出し、プロンプトに差し込んでおく- 返却させる JSON は以下のように定義する
is_passed: 合否score: 0-100 のスコアfeedback: 記事に対するフィードバック
なお、このプロンプトは Anthropic の Prompt generator を使ってベースを作成し、調整を加えました。
4. エラーを通す
それでは実際にテストを実行してみます。npm script に "test": "vitest run" を記述したうえで、以下を実行します。ARTICLE_PATH には記事のパスを指定します。
ARTICLE_PATH="/path/to/article.md" pnpm test
この段階では、記事本文はまだ空の想定なので、「評価ができません」といった旨のフィードバック(エラー)が得られることを期待します。
実際に実行すると、以下のようにエラーが確認できました。TDD でいう「レッド」の状態ですね。
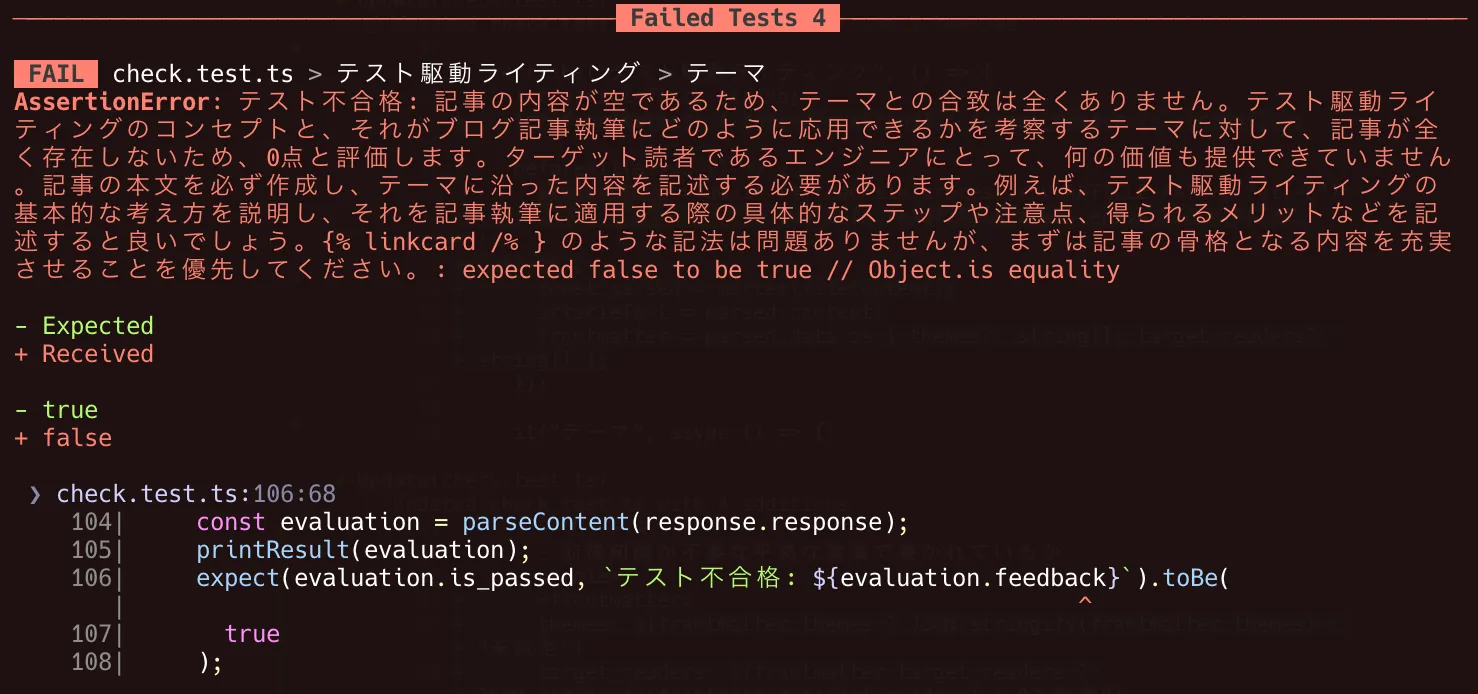
Fig. 1 エラーを確認する
5. テストを通す(記事を書き始める)
ここまできたらテスト駆動で記事を書く環境が整ったので、実際に記事を書き進めます。 自分のスタイルで書き進めながら、時々 pnpm test でテストを実行してみます。
ざっと記事を書いたあとにテストを実行すると、よほど内容がテーマとズレていない限りは、テストをパスします。TDD でいう「グリーン」になりました。
例えば、実際に本記事の執筆途中でテスト実行して得られたフィードバックを下記に示します。

Fig. 2 執筆途中のフィードバック
上記のテストを実行したタイミングは、先にセクションを作成してアウトラインを整えた後に、半分程度勢いで記事を書き進めていた頃でした。 メリットやデメリットは箇条書きで仮置きしている程度だったので、「メリット・デメリットをもっと具体的に書け」はもっともな指摘だと思います。
このように、適当なタイミングでテストを実行しつつ、フィードバックを気軽に繰り返し受け取ることで、文章をブラッシュアップすることができます。TDD でいう「リファクタリング」を進めていく感覚と言えそうです。
ここまでで、「テスト駆動ライティング」の実践を一通り行うことができました。 最後に、実際にやってみて良かった点、そしてもう少し改善できそうな点を自分なりに振り返ってみようと思います。
良かった点
テスト駆動ライティングの実践を通じて良かったと感じた点は下記のとおりです。
- テーマ (=仕様) を先に考えるという強制力が働く
- ペアライティングの感覚で執筆を進められる
- API コストを気にしなくて良い
テーマを先に考えるという強制力
これまでに何度か触れているように、やはりテストケースの作成を通じて「チェックしたいポイント」を先に考えることで、記事の全体像を想像できるように強制できるのは1つのメリットです。
正直、伝えたいテーマや主題、アウトラインを先に考える、というのは記事執筆における基本的なお作法であり、このような仕組みが無くてもできる人はできると思います。
しかし、全体像をよく考えずに書き始めてしまいがちな自分のような人間にとっては、良い補助輪になる感覚があります。
ペアライティングの感覚
テストを実行するたびにフィードバックをくれるため、ペアプログラミングならぬペアライティングを実施しているような感覚を持てることも良い点と言えるでしょうか。
あくまでも自分がハンドルを握りながらも、適宜チェックをしてサポートしてくれるパートナーです。 書くのが少し楽しくなるような感覚すらあります。
API コストを気にしなくて良い
テスト駆動にライティングを進めるにあたっては、何度も繰り返しテストを実行できることが理想です。 LLM を繰り返し実行するとなると気になるのが呼び出しコストですが、ローカル LLM を利用することで費用を気にせず実行できるのは良い点といえます。
改善できそうな点
一方で以下のような点を改善できそうです。
- テスト実行に時間がかかる
- 評価がブレたり、甘くなったりすることがある
- テストケースの書き方の自由度が高く、改善の余地がある
テスト実行に時間がかかる
利用している PC の環境にもよりますが、API で利用できる高性能な LLM に比べると、ローカル LLM の呼び出しには時間がかかることが多いです。
例えば、自分の環境では4つのテストケースを実行するのに2分弱かかりました。
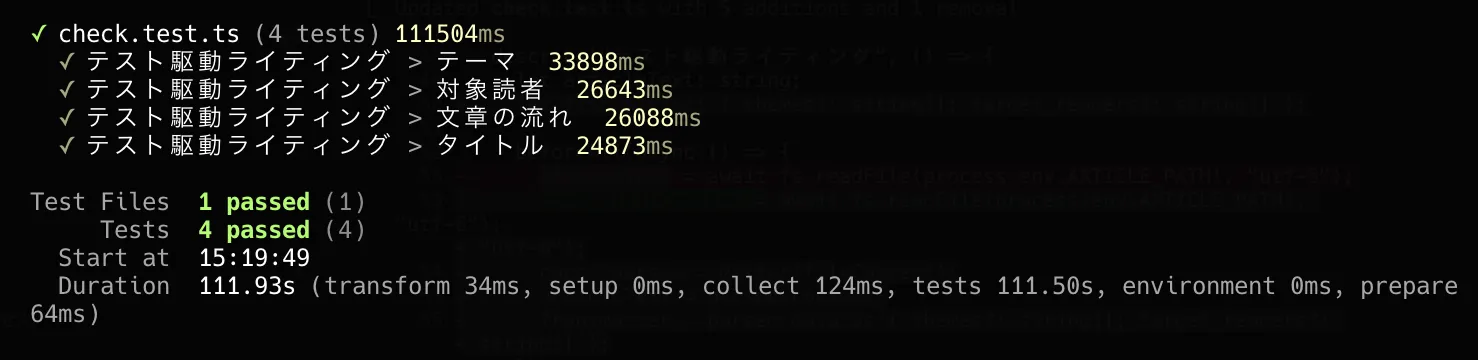
Fig. 3 テスト実行時間
繰り返しテストを実行するうえでは、短い時間でテストを実行できるのが理想です。このあたりは改善の余地がありそうです。
具体的な改善策としては、以下のようなものがあるでしょうか:
- より軽量なモデルを使う (性能とのトレードオフ)
- 並列実行を工夫する
- 外部の API を使う (コストがかかる)
外部 API 呼び出しに関しても選択肢は色々ありますが、Ollama も Turbo という機能を Preview で公開しています。
また、Gemini CLI や Claude Code が使える場合は、-p オプションを利用することで non-interactive mode で実行するのも手でしょう。 ただし、出力の構造化を強制できない認識なので、自前で仕組みを作る必要がありそうです。
評価がブレる・甘い
LLM は確率的に動作するという特性上、どうしても生成される評価がブレることがあります。 例えば、内容を変えていなくても評価の内容が変わったりすることはよくあります。
また、評価が甘くなる傾向にもあります。 プロンプトで「厳しく」「率直な」意見を求めても、求める厳しさを得られないことがあります。
これらはプロンプトエンジニアリングで工夫したりする余地がありそうです。 しかし、プロンプトの書き方に画一的な正解は無いですし、使うモデルによっても最適な書き方は変わってくるので、地道に頑張るしかなさそうです。
プロンプトエンジニアリングは各社がいろいろなプラクティスを公開していたりするので、参考にしつつ上手に書けるようになりたいものですね。
テストケースのブラッシュアップ
今回、デモ的に作成したテストケースは、もっと詳細化したり、記事の内容に応じてカスタマイズできると考えています。
実際に利用していく中で、チェックしたいポイントを随時追加しながら、テスト駆動的に書き進められたらよいなと思っています。
まとめ
以上、Ollama と Vitest を使って、記事の品質を繰り返し評価できる TDD ライクな仕組み「テスト駆動ライティング」を試してみた話でした。
ブログ記事の執筆と LLM を組み合わせる方法の中で、よく行われるものの1つが「ChatGPT などのチャット UI に書いた記事を貼り付けてフィードバックを得る」というものでしょう。 この方法でも十分参考になると思いますし、ここまで書いておいてなんですが、正直わざわざローカル LLM で、テスト駆動にやる必要はまったくないと思います。
しかしながら、記事の目的や構造を自分で考えながら自分で書き進めたい、という状況においてはテスト駆動は非常に良い仕組みだと感じます。
また、ローカル LLM の1ユースケースとして、手元で実際に動かすことを体験したり、今後新しいモデルが公開されたら差分を試してみたりと、肌感覚を得るにはぴったりです。
運用していくなかで、テストケースやプロンプトを改善していき、より文章執筆が捗る環境が手に入ったら最高ですね。
ここまでお読みいただきありがとうございました。